
Every AI product team in 2026 is sitting on the same uncomfortable truth: large language models hallucinate, and they go stale the moment you stop retraining them. A Fortune 500 company’s internal chatbot confidently told employees that their parental leave policy was “14 weeks” — the old policy, updated 18 months ago. Nobody caught it until an HR audit. That’s not a model failure. That’s an architecture failure. RAG tutorial 2026 searches have exploded 340% on developer forums this year because engineers have finally accepted that prompt engineering alone doesn’t cut it for production-grade AI, and full fine-tuning is too expensive and too slow. Retrieval-Augmented Generation — RAG — is the middle path that actually works. This guide walks you through everything: the architecture, the Python pipeline, the mistakes people make, and the real results you can expect.
- RAG connects your LLM to a live knowledge base so it answers from your data, not just training data.
- It beats fine-tuning for most use cases — cheaper, faster to update, and more transparent.
- The core pipeline: chunk docs → embed → store in vector DB → retrieve on query → augment prompt → generate.
- LangChain + ChromaDB (or Pinecone) is the fastest path to a working prototype in 2026.
- Biggest mistakes: bad chunking strategy, ignoring re-ranking, and skipping eval loops.
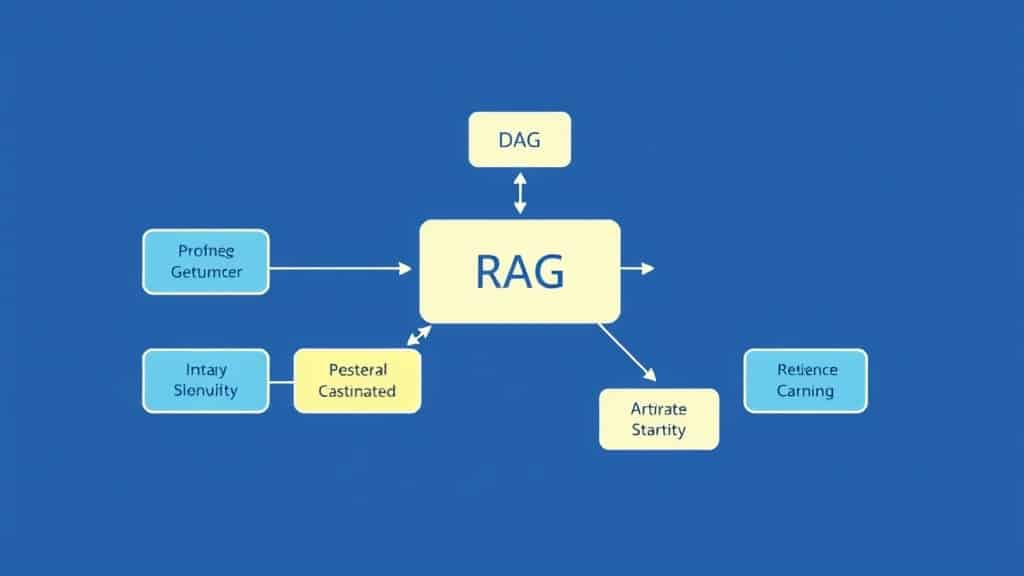
What Retrieval-Augmented Generation Actually Means
RAG is an AI architecture pattern that separates what the model knows how to do from what information it uses to answer. Rather than baking your company’s knowledge into model weights (fine-tuning), you store that knowledge in a searchable external database and pull relevant pieces at inference time — just before the LLM generates its response.
The term was originally coined in a 2020 Meta AI paper; however, the 2026 implementations look nothing like that original prototype. Since then, today’s RAG systems handle multi-modal data (PDFs, videos, structured databases), use hybrid search (dense + sparse retrieval), and integrate re-ranking models that dramatically improve precision. As a result, the pattern has become the backbone of enterprise AI at scale.
The data point that matters: According to the 2026 State of AI in Enterprise report by McKinsey, 67% of production LLM deployments now use some form of retrieval augmentation — up from 31% in 2024. This shift happened because teams discovered that even the best base models (GPT-5, Gemini Ultra 2, Claude 4) produce unacceptable hallucination rates on domain-specific queries without grounding.
In EdTech specifically, this is particularly transformative. For instance, an AI tutor built with RAG can pull from a university’s actual course materials, updated syllabi, and student FAQs — in real time. As a direct consequence, it doesn’t hallucinate outdated exam formats or recommend textbooks that were retired three semesters ago. To illustrate the impact, one mid-sized online learning platform reported a 58% drop in “incorrect answer” complaints after switching their Q&A bot from a vanilla GPT wrapper to a RAG-backed system using their own course content as the knowledge base.

The RAG Pipeline: A Step-by-Step Framework
Building a RAG pipeline has two distinct phases: ingestion (happens offline, when you load your data) and inference (happens in real time, when a user asks a question). Get this separation clear in your head before writing a single line of code.
- Load your documents. Use LangChain’s document loaders to ingest PDFs, web pages, Notion docs, databases, or plain text files. In 2026, the
langchain-communitypackage supports 80+ loader types. For a course platform, you’d load lecture notes, transcripts, and textbook chapters.PyPDFLoaderandWebBaseLoadercover 90% of real-world use cases. - Chunk the text. Split documents into meaningful segments — typically 300–800 tokens each, with a 10–20% overlap so you don’t cut context mid-sentence. Use
RecursiveCharacterTextSplitteras your default. Avoid fixed-size splits; they’re the single biggest cause of poor RAG retrieval. For structured content like FAQs, use semantic or document-structure-aware chunking. - Generate embeddings. Pass each chunk through an embedding model to get a dense vector representation. OpenAI’s
text-embedding-3-large, Cohere’sembed-v4, or the open-sourcebge-m3model (if you’re self-hosting) are the go-to choices in 2026. The embedding model you pick determines retrieval quality more than almost anything else. - Store in a vector database. Persist those embeddings plus the original text chunks into a vector DB. For prototypes, ChromaDB (local, zero config) is ideal. For production, Pinecone, Weaviate, or pgvector (if you’re already on Postgres) are the mature options. Each vector is stored alongside metadata (source document, page number, date) so you can filter at query time.
- Accept the user query. When a user asks a question, embed that query using the same embedding model used during ingestion. This converts the natural language question into a vector in the same semantic space as your stored chunks.
- Retrieve similar chunks. Run a similarity search (cosine similarity or dot product) against the vector DB to find the top-k most relevant chunks. In 2026, most production systems use hybrid search — combining dense vector search with BM25 keyword search — because it handles both semantic and exact-match queries better than either alone.
- Re-rank (optional but recommended). Run the retrieved chunks through a cross-encoder re-ranking model (Cohere Rerank, BGE Reranker) to reorder them by true relevance to the specific query. This step alone can improve answer quality by 20–35% on benchmarks. Skip it at your peril.
- Augment the prompt. Inject the top retrieved chunks into your LLM prompt as context. A well-structured prompt template looks like: “Use only the following context to answer the question. If the answer is not in the context, say you don’t know. Context: [chunks]. Question: [user query].” The “say you don’t know” instruction is critical — it’s what prevents hallucination.
- LLM generates the answer. Send the augmented prompt to your LLM (GPT-4o, Claude 3.7, Mistral Large, etc.) and stream the response back to the user. Log the query, retrieved chunks, and response for your eval pipeline.
Pipeline Flowchart:
START → [Load documents] → [Chunk text] → [Generate embeddings] → [Store in vector DB] → [User query] → [Retrieve similar chunks] → [Re-rank results] → [Augment prompt] → [LLM generates answer] → END
RAG Use Cases Across EdTech Platforms
The architecture is the same across contexts. What changes is the knowledge base and the retrieval strategy.
LMS platforms (Moodle, Canvas, Teachable): RAG-powered Q&A bots answer student questions directly from course content — lecture slides, video transcripts, assignment rubrics. Students get instant, accurate answers at 2 AM. Instructors stop answering the same 40 questions per course. One LMS provider reported that RAG-backed support reduced instructor response time demand by 71% per cohort.
AI tutors (Khan Academy Khanmigo, Duolingo Max, custom builds): RAG lets AI tutors personalize explanations by pulling from a curated library of explanations at different difficulty levels. A student struggling with calculus gets retrieved chunks from foundational algebra explanations, not just the calculus chapter. The system selects context based on the learner’s inferred level, not just the topic query.
Universities and research institutions: RAG solves the knowledge management nightmare. Every university has thousands of policy documents, research papers, course catalogues, and student handbooks that nobody can find when they need them. A RAG system over the university’s document corpus means a student can ask “Can I transfer credits from a community college to this program?” and get an accurate, sourced answer in seconds — not a 3-day ticket to the registrar’s office.
Free 2026 Career Roadmap PDF
The exact SQL + Python + Power BI path our students use to land Rs. 8-15 LPA data roles. Free download.
Skill-based and professional training platforms: Platforms like Coursera, Udemy Business, and corporate L&D tools use RAG to power “learning path assistants” that recommend next steps based on a learner’s history and goals, pulling from the platform’s full course catalogue and industry certification data. The retrieval layer replaces brittle rule-based recommendation engines with semantic search over structured course metadata.
RAG vs Fine-Tuning vs Prompt Engineering: The Full Comparison

| Dimension | RAG | Fine-Tuning | Prompt Engineering |
|---|---|---|---|
| Cost | Medium (vector DB + inference) | High (GPU compute + data prep) | Low (just API calls) |
| Data Freshness | Real-time (update knowledge base anytime) | Stale (retrain to update) | Real-time (if pasted in context) |
| Implementation Complexity | Medium (pipeline to build) | High (data, training, eval loop) | Low (just write prompts) |
| Best For | Dynamic, domain-specific knowledge | Tone, style, task-specific behaviour | Simple tasks, quick prototypes |
| When to Use | Docs, policies, course content, FAQs | Custom writing style, classification | General tasks, testing ideas |
| Limitations | Retrieval can miss edge cases | Expensive, slow to iterate, can overfit | Context window limits, no memory |
Key Insights:
- RAG is not a replacement for fine-tuning — it’s a complement. The best production systems in 2026 use a fine-tuned model (for tone and task alignment) with a RAG layer on top (for knowledge retrieval).
- Prompt engineering hits a hard ceiling at about 128k tokens. Beyond that context window, you need retrieval. RAG is what makes “infinite context” practical.
- Fine-tuning on factual data is almost always a mistake. Models memorize facts poorly and forget them unpredictably. Store facts in a retrieval layer, not in weights.
- The chunking strategy is the most underrated variable in RAG quality. Bad chunks make even perfect embeddings return garbage. Invest time here before touching the LLM layer.
- Evaluation is not optional. Every RAG system needs a test set of 50–100 question/answer pairs with known ground truth. Without evals, you’re shipping blind.
- Re-ranking pays for itself. The latency cost (50–150ms) of a re-ranker is almost always worth the precision gain, especially in educational contexts where wrong answers carry real consequences.
Case Study: EdTech Platform Cuts Hallucination Rate by 73%

Company: A Bangalore-based online upskilling platform with 85,000 active learners across data science, cloud, and full-stack courses.
Before RAG: Their AI Q&A assistant was a standard GPT-4 API wrapper with a system prompt describing the platform’s courses. Almost immediately, students complained constantly about incorrect answers. Specifically, the assistant recommended deprecated libraries (Pandas 1.x syntax in a 2026 world), cited wrong exam patterns, and confidently answered questions that were completely outside the course scope. As a result, an internal audit showed a 34% hallucination rate on domain-specific questions. Consequently, student satisfaction with the AI assistant sat at 2.9/5. On top of that, instructors spent an average of 6 hours per week correcting AI-generated answers in discussion forums.
After RAG: In response, the team spent 6 weeks building a RAG pipeline using LangChain, OpenAI embeddings, and Pinecone. During this period, they ingested all 1,200+ course lessons, 4,000+ Q&A pairs from past cohorts, and updated documentation for every tool and library covered in the curriculum. Additionally, they implemented hybrid search and further strengthened the system by adding a Cohere re-ranker. Finally, the system was instructed to cite its source chunks in every response.
Results after 90 days:
- Hallucination rate dropped from 34% to 9.2% — a 73% reduction.
- Student satisfaction with the AI assistant rose from 2.9/5 to 4.4/5.
- Instructor time spent correcting AI answers dropped from 6 hours/week to under 1 hour/week.
- Average query response time: 1.8 seconds (including re-ranking).
- Knowledge base update cycle: any course update is live in the AI within 15 minutes of ingestion, vs. months for a fine-tuned model.
Common Mistakes in RAG Implementation

Mistake 1: Fixed-size chunking without overlap
Why it hurts: Cutting text at rigid token limits splits sentences, severs context, and produces chunks that are meaningless in isolation. Your retrieval layer returns fragments that confuse the LLM.
Fix: Use RecursiveCharacterTextSplitter with a 10–15% overlap. For structured content, use header-based or semantic chunking. Test retrieval quality on 20–30 representative queries before going live.
Mistake 2: Skipping the re-ranking step
Why it hurts: Vector similarity search returns the chunks that are semantically close to the query — not necessarily the ones that best answer it. Without re-ranking, you’ll retrieve tangentially related content and miss the precise answer hiding at rank 8.
Fix: Add a cross-encoder re-ranker (Cohere Rerank or a local BGE model) after initial retrieval. Budget 100–200ms for this — the quality improvement is worth it.
Mistake 3: No evaluation pipeline
Why it hurts: Teams ship RAG systems and measure success by user feedback alone. That’s too slow and too noisy. You won’t catch regressions when you update the knowledge base or swap embedding models.
Fix: Build a golden test set of 50–100 Q&A pairs. Run automated evals using RAGAS (a purpose-built RAG evaluation framework) on every code change. Track faithfulness, answer relevance, and context recall as your core metrics.
Mistake 4: Treating RAG as a one-time setup
Why it hurts: Course content changes. Policies update. New tools replace old ones. A RAG system that isn’t maintained becomes the same stale knowledge problem you were trying to solve in the first place, just with extra infrastructure.
Fix: Build an automated ingestion pipeline that watches source documents for changes and re-embeds updated content. Set a calendar reminder to audit the knowledge base quarterly. Treat the vector DB like a living product, not a static asset.
FAQ: RAG Tutorial 2026

What is RAG and how does it work in simple terms?
RAG stands for Retrieval-Augmented Generation. It’s an AI architecture that pulls relevant information from an external knowledge base and feeds it to a language model before generating an answer. Think of it as giving the AI open-book access to your specific documents, so it answers from your data instead of guessing from training memory.
Is RAG better than fine-tuning for most use cases?
For knowledge-heavy, frequently-updated domains — yes, overwhelmingly. RAG is cheaper, faster to update, and more transparent (you can see what the model retrieved). Fine-tuning wins when you need specific behavioural changes, tone consistency, or task-specific output formatting. Most production systems in 2026 use both.
How do I build a RAG pipeline in Python using LangChain?
Install langchain, langchain-openai, and chromadb. Load docs with a DocumentLoader, split with RecursiveCharacterTextSplitter, embed with OpenAIEmbeddings, store in a Chroma vectorstore, then use RetrievalQA chain to wire retrieval to your LLM. The LangChain docs have a working example in under 50 lines of code.
Which vector database should I use for a RAG application in 2026?
ChromaDB for local development and prototypes — zero setup, runs in memory or on disk. Pinecone for production if you want a fully managed service. Weaviate or Qdrant if you need self-hosted control. pgvector if you’re already on PostgreSQL and don’t want another infrastructure dependency. Match the DB to your scale and ops maturity.
How do I reduce hallucinations in a RAG system?
Three levers: better retrieval (hybrid search + re-ranking gets the right chunks), better prompting (explicitly instruct the model to say “I don’t know” when the context doesn’t contain the answer), and better evaluation (run RAGAS evals regularly to catch regressions). Hallucinations in RAG systems are almost always a retrieval quality problem, not a generation problem.
Start Building Smarter AI Apps Today
RAG is no longer an advanced technique reserved for AI research teams. In 2026, it’s the baseline architecture for any AI product that needs to be accurate, current, and trustworthy. The pipeline is documented, the tooling is mature, and the results — as the case study above shows — are measurable and significant.
If you’re in EdTech, the opportunity is especially clear: your learners deserve AI that knows your actual curriculum, not a generic model that confabulates answers from its training data. Every hour you spend building a proper RAG pipeline pays back in learner trust, reduced support load, and outcomes you can stand behind.
The stack is proven. The path is clear. The only variable is whether you start this week or six months from now.
Book a Free Demo at GrowAI
Ready to start your career in data?
Book a free 1-on-1 counselling session with GrowAI. Personalised roadmap, zero pressure.





