
LLMOps: The Part of AI Development Nobody Talks About (Until the Bill Arrives)
Your AI feature shipped. Users love it. The team is celebrating. Then the invoice arrives: ₹18 lakh for the month. Your CPO is asking why the AI cost more than your entire cloud infrastructure. You don’t have a good answer because you never set up cost monitoring.
That’s a real scenario that plays out regularly in 2026. Teams invest months building excellent AI features and treat operations as an afterthought. Three months into production, they’re dealing with unexplained cost spikes, silent quality degradation, and user-facing failures with no tracing to understand what happened.
LLMOps is the discipline of running LLMs reliably in production. It’s unglamorous, undervalued, and absolutely essential. Here’s the practical version — no buzzword bingo, just what you actually need.
- LLMOps covers: observability (tracing every LLM call), evaluation (measuring output quality), cost management, prompt versioning, and safety monitoring.
- Without evals, you cannot know if a code change or prompt update made quality better or worse.
- Langfuse (open source, self-hostable) is the most practical observability tool for teams who care about data privacy.
- Semantic caching, model routing, and prompt compression can reduce LLM API costs by 40–60%.
- Prompt drift is the #1 silent production failure: LLM providers update models, and your prompts produce different outputs without any code change on your end.
The 5 Layers of LLMOps
Think of these as floors in a building. You need the foundation before the upper floors:
| Layer | What it covers | Tools (open source first) | What breaks without it |
|---|---|---|---|
| Observability | Trace every LLM call: input, output, latency, cost, user ID | Langfuse, LangSmith, Phoenix | Zero visibility into failures or cost drivers |
| Evaluation | Automated quality measurement against golden dataset | RAGAS, DeepEval, Promptfoo | Silent quality degradation from model updates or prompt changes |
| Prompt management | Version control for prompts with rollback capability | Langfuse prompts, Humanloop, PromptLayer | Untracked prompt changes breaking production |
| Cost management | Per-feature, per-user, per-model cost tracking | Helicone, OpenMeter, custom | Surprise invoices, no visibility into cost drivers |
| Safety monitoring | Input/output filtering, PII detection, policy enforcement | LlamaGuard, Guardrails AI | Safety incidents, data leakage, policy violations |
Implementation Priority (Start Here)
- Instrument first, build features second. Integrate Langfuse into your LLM code before you ship anything. Every call should create a trace with: prompt version, model name, input tokens, output tokens, latency, user ID, and feature name. Retrofitting observability after launch means working backwards through opaque failures.
- Build your evaluation dataset before launch. Get 100–200 (input, ideal output) pairs from domain experts. This is your golden test set. Run evals on every prompt change before deploying. Without this, you’re flying blind when you update prompts.
- Set up cost alerts at 80% of monthly budget. LLM cost spikes happen suddenly. A prompt change that doubles average response length doubles inference cost overnight. Alert before the surprise, not after.
- Add prompt version control. Never edit a production prompt in code without creating a version. Use Langfuse prompts or Humanloop to track which prompt version is in production, what it replaced, and what quality metrics it achieved.
- Monitor for drift weekly. Schedule automated checks: this week’s quality metrics vs. last month’s baseline. LLM providers update models without announcement — your prompts produce different outputs starting from a random Tuesday morning. Drift detection catches this before users notice.
The biggest LLMOps ROI is usually semantic caching. For FAQ-style applications, 30–40% of queries are semantically identical. Cache the response to the first query; return it for similar ones. Typical implementation time: 2 days. Typical cost reduction: 25–35%.
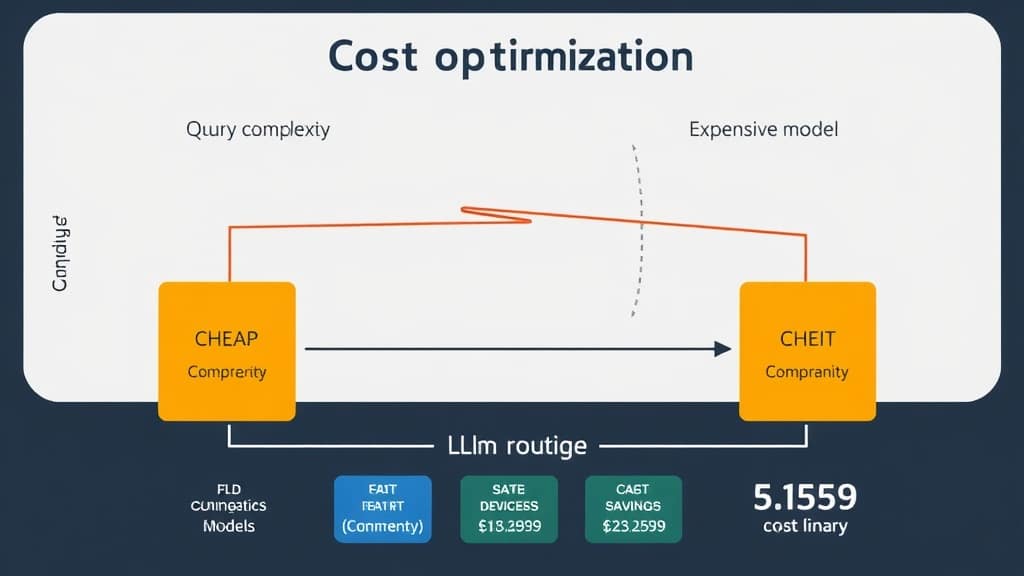
Cost Optimization: The Three Moves That Work
Model routing: Classify incoming queries by complexity. Simple FAQ questions → GPT-4o mini or Llama 4 Scout (₹0.10/M tokens). Complex reasoning → GPT-4o (₹2.50/M tokens). Done correctly, this reduces costs by 40–60% with minimal quality impact. The routing classifier itself is cheap to run — a small model or even a keyword-based heuristic works for many cases.
Semantic caching: Use a vector database to store previous (query, response) pairs. For each new query, check if a semantically similar one has been answered before (cosine similarity > 0.95). Return the cached response. For EdTech platforms with many students asking similar questions, this frequently saves 30% of API costs. gptcache or a custom Qdrant implementation both work.
Prompt compression: Long context windows cost proportionally. LLMLingua (Microsoft, open source) compresses prompts by removing non-essential tokens while preserving meaning — typically 3–5x compression with <5% quality loss. For RAG applications with long retrieved contexts, this is often the fastest cost win available.
Free 2026 Career Roadmap PDF
The exact SQL + Python + Power BI path our students use to land Rs. 8-15 LPA data roles. Free download.
Case Study: ₹8 Lakh Per Month in Savings
An AI tutoring platform was spending ₹22 lakh per month on OpenAI API with no visibility into what was driving costs. They knew the number; they didn’t know why.
Step 1: Langfuse instrumentation across all features. Within a week, the data was clear: the FAQ feature was making 40,000 daily API calls for questions with answer similarity >0.95 — essentially the same questions over and over. No caching had been implemented.
Step 2: Semantic caching on the FAQ feature. 38% of queries now returned cached responses. Step 3: Model routing — GPT-4o mini for questions classified as “factual retrieval” (70% of volume), GPT-4o for “conceptual explanation” (30%).
Step 4 (bonus discovery from eval monitoring): Essay feedback quality had silently degraded by 15% after an OpenAI model update two months earlier. They reverted to a pinned model version and quality recovered. They’d lost two months of quality without knowing it.
Result: Monthly cost went from ₹22 lakh to ₹14 lakh — ₹8 lakh per month saved. The observability work that enabled this took one engineer two weeks to implement. ROI measured in weeks.
Common Mistakes
- Using a different model version in dev vs. prod. If your evals run on GPT-4o-2024-08-06 but production uses the auto-updated “gpt-4o” endpoint, your evals don’t protect you from model changes. Always pin model versions in production.
- Human review as your only evaluation. It doesn’t scale. Build automated LLM-as-judge evals using Claude or GPT-4o to evaluate your production model’s outputs against a quality rubric. RAGAS for RAG-specific metrics. Correlates well with human judgment and runs 1,000x faster.
- No budget ownership. If no engineer owns the AI cost budget, it drifts upward unchecked. Assign it explicitly, set targets, review monthly.
FAQ
Langfuse vs LangSmith — which should I use?
Langfuse: open source, self-hostable (free), better for privacy-conscious teams. LangSmith: managed service with deeper LangChain integration, better developer experience for LangChain-heavy projects. Both are production-ready in 2026.
How do I evaluate LLM outputs automatically?
Use LLM-as-judge: prompt GPT-4o or Claude with your quality rubric and the output to evaluate. “On a scale of 1–5, how well does this response explain the concept to a beginner?” Correlates well with human judgment and scales to thousands of evaluations daily.
What’s prompt drift and how common is it?
Prompt drift is when your prompt produces different outputs not because you changed the prompt, but because the model changed. OpenAI, Anthropic, and Google update models regularly. Without weekly eval monitoring, teams typically notice drift only after user complaints — usually 4–8 weeks after it starts.
Do I need LLMOps tools for a small app?
Even for a small app with 100 daily users: add Langfuse tracing (free self-hosted) and a 50-example eval dataset. This costs almost nothing and saves enormous debugging time when something goes wrong — and something always goes wrong eventually.
The Core Insight
LLMOps is the infrastructure work that lets you improve your AI product with confidence rather than hope. Without it, every prompt change is a leap of faith, every cost spike is a mystery, and every quality degradation is invisible until users are already frustrated. The tools are mature, most are open source, and the investment pays for itself within weeks of implementation.
Build AI systems that run reliably at scale — join GrowAI
Live mentorship • Real projects • Placement support
Ready to start your career in data?
Book a free 1-on-1 counselling session with GrowAI. Personalised roadmap, zero pressure.





